微软新AI VALL-E只需用秒音频,可以模拟任何人的声音
文章目录[隐藏]
微软刚刚推出了 VALL-E(语音感知语言学习编码器-解码器),这是一种新的文本转语音人工智能模型,只需三秒的音频样本即可模拟任何人的声音。VALL-E 基于 Meta 的 EnCodec 音频压缩技术,该技术利用人工智能将高质量音频压缩到远低于 MP3 文件的数据速率。
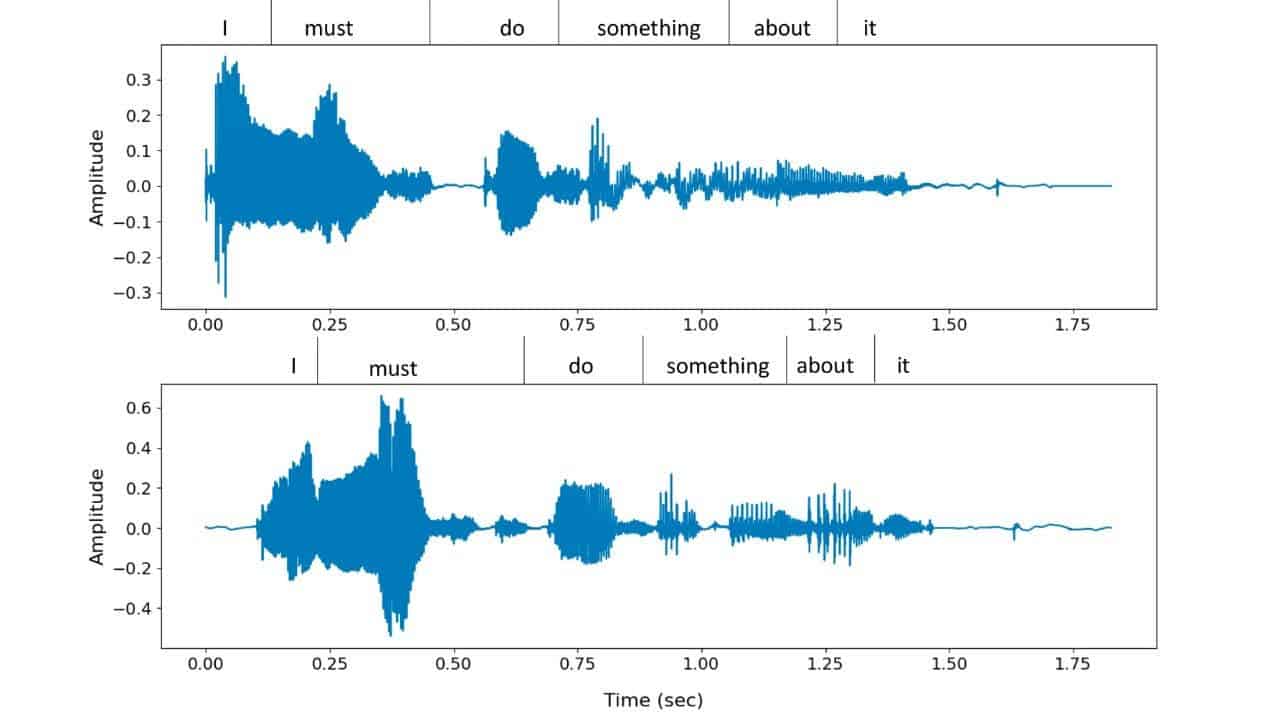
微软的新人工智能可以保留演讲者的情绪基调和声学环境。
VALL-E 背后的技术是开创性的,因为它允许模型分析一个人的声音,然后将这些信息分解为称为“令牌”的离散组件。VALL-E 可以使用此信息来匹配它“知道”的信息,即如果该声音说出除三秒样本之外的其他短语,该声音将如何发音。
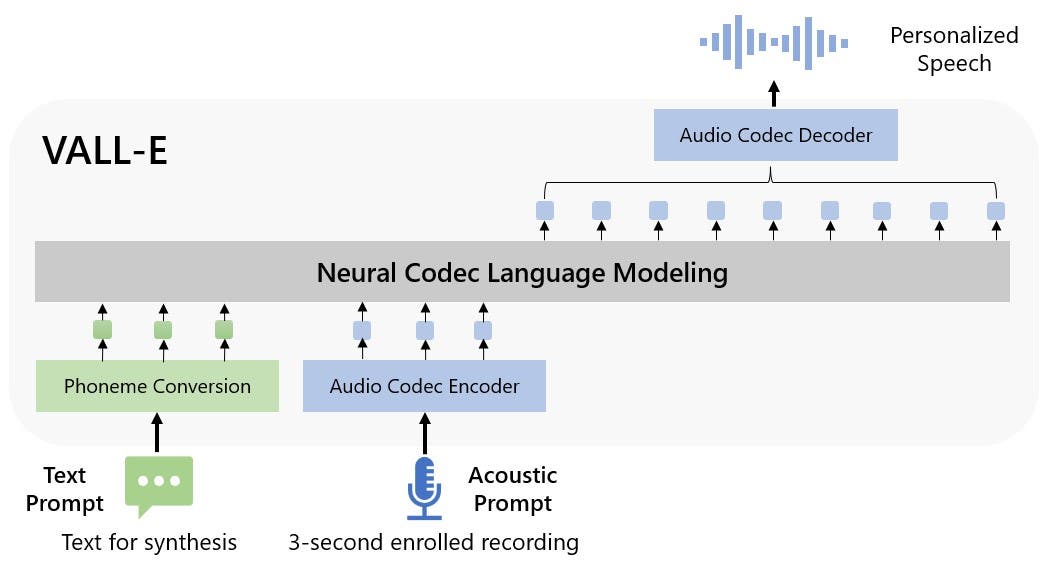
如今的文本转语音系统需要高质量、非常干净的训练数据,并且是在配备专业设备的录音室中完成的。微软在 VALL-E 领域取得了进展,允许该模型仅使用三秒的样本来模拟任何人的声音。VALL-E 现在可以模拟几乎任何人的声音,而无需他们在工作室里呆上几周。
VALL-E 的功能是使用 LibriLight 音频库进行磨练的,该库包含超过 7000 个发言者的 60K 小时的语音。这使得 VALL-E 能够生成听起来逼真的英语语音。当与其他生成式人工智能模型结合时,它具有高质量文本转语音应用的潜力。
Microsoft 提供了大量VALL-E 生成的样本,可以亲自聆听。虽然结果并不完美,但 VALL-E 生成的样本听起来很自然,与原始声音样本没有区别。
尽管 VALL E 的功能令人印象深刻,但 Microsoft 意识到该技术可能被滥用。据该公司称,有害人员可以将音频用于恶意目的,例如欺骗语音识别或冒充。为了减轻这些风险,微软建议开发一种检测模型来区分 VALL-E 生成的合成语音和真实语音。
最后,VALL-E 是文本转语音技术的重大进步。它仅使用三秒音频样本即可模拟任何人的声音,这对于各种用途来说都是革命性的。但是,Microsoft 必须继续改进 VALL-E,同时确保采取适当的保护措施以防止其滥用。