AI音频:传统音频水印技术与谷歌AI音频水印技术
音频水印,对于我们很多人是一种传说,可它是真的存在的一种技术,大部分音频水印是为了给音频的写入一些它的元数据,方便人们使用。而国内可能最关注的是,音频水印是一些音效、音源、音频软件的防盗版方式,一些人使用盗版音效的过程中害怕音频水印,但总是以“掩目盗听”来逃避。
音频水印
使用音频水印作为识别方法可能不是完全不言自明的。本质上,音频水印解决了一个更普遍的问题,即通过声音发送附加数据(下面将详细介绍)。如果水印作为将所需信息嵌入音频中的元数据的引用,我们可以使用这些附加数据来识别音频。
一旦音频被加上水印,手机(或其他设备)就可以提取水印并解引用元数据,从而了解有关音频所需的信息。下图说明了此过程:

使用水印技术进行音频识别的步骤
在图示中,水印ID被添加到原始音频中,从而创建了加水印的音频(蓝色波形)。水印ID唯一地标识外部元数据数据库中的元数据。元数据数据库可以存在于云中或手机的本地。当手机使用其内部麦克风捕获音频时,它可以从中提取水印。可以对水印进行解引用以获得音频元数据。
使用音频水印进行识别具有以下优点:
· 音频水印可以从任何带有麦克风的设备上的音频中检测和提取出来。不需要蓝牙、WiFi或其他连接。水印提取是省电的,甚至可以在旧的和/或慢速的硬件上运行。
· 水印识别的扩展性非常好。无论想要识别多大的音频集,检测都像提取水印一样简单。此外,由于不需要服务器,因此增加用户群也不会产生任何成本。
· 音频水印可以区分对人类来说无法区分的素材。例如,一首歌在Spotify上的水印可能与Apple Music上的不同,允许水印检测确定播放来源。
总的来说,音频水印提供了一种有效、可扩展且低成本的方法来识别和跟踪音频内容。它在各种设备和环境下都能可靠地工作,不需要特殊的连接或硬件要求。这使得它在许多应用中都是一个有吸引力的选择,从版权保护到内容跟踪和播放源识别等。
超声水印
可能最明显的隐藏声音以避开人类的方法是将其隐藏在人类听觉频谱之外。人耳和大脑协同工作,处理大致在20Hz到20kHz之间的声音,如下图所示。

人类对不同频率的声音水平阈值
该图像显示了不同频率的声音级别阈值。这表明人类听觉系统只能感知到足够响度的声音。能感知到的声音响度随频率和年龄组的不同而变化。在实践中,这意味着人类往往无法感知到16kHz以上的声音,而且这个阈值会随着年龄的增长而进一步降低。因此,超出16kHz的音频频谱有时被称为超声范围。
考虑到手机(或其他)麦克风可以捕获部分超声范围的声音,因此可以添加额外的数据。在这个频率范围内添加数据的优点是非常简单,因为我们不必担心会影响音频质量。因此,这种技术允许嵌入大量数据。
然而,超声水印的一个问题是水印很容易被移除。由于水印以与主要内容明显不同的频率存在,因此可以在不影响内容的情况下移除水印。这使得该技术在取证方面无效。
此外,水印的移除并不总是故意的。由于人类无法听到超声,因此在压缩过程中经常会将其移除。例如,下图显示了如果我们将文件上传到YouTube或Vimeo会发生什么情况。

白噪音片段(原始为蓝色)上传到热门视频平台后的频谱(频率分布)
我们可以看到,如果将一个每个频率幅度恒定的输入上传到YouTube或Vimeo,流媒体服务的压缩算法会分别移除高于15.8kHz或17.0kHz频率的音频内容。这个数字是在每个服务中可用的最佳上传和播放设置下得出的。这意味着,一旦视频被上传,任何添加到最大频率之外的水印都会丢失。
超声压缩不仅限于YouTube和Vimeo。以下图像分别是来自Netflix和BBC iPlayer的音频频谱分析。


这些数字表明,Netflix的压缩算法对10kHz以上的音频进行了强烈压缩,而BBC iPlayer则移除了15kHz以上的所有内容。尽管这些数字可能在一定程度上依赖于网速和合同类型(在Netflix的情况下),但这些频道上的大部分内容都将被去除水印。这些压缩算法甚至在电视广播中也是活跃的,尽管在这些情况下,质量会根据合同、地理位置和频道的不同而有很大差异。
扩频水印
与超声水印相关的缺点导致了扩频水印的发明和使用。扩频水印最初用于图像水印,但后来经过修改也可用于音频。顾名思义,这种技术的思想是将水印分布在整个频谱上。这意味着水印与实际内容交织在一起,使得去除水印变得困难。并且由于水印存在于与内容相同的频率范围内,因此它不会被压缩算法移除。
由于水印存在于与内容相同的频率范围内,我们必须更加小心地放置它。为了避免降低原始内容的质量,水印必须利用人类听觉的弱点来避免被察觉。扩频水印通常以低幅度噪声的形式添加在整个频谱上。只要原始内容包含足够宽的频率范围,人类听觉系统就不会注意到低级别的噪声。
扩频水印解决了超声水印的许多问题和限制,但它本身也并非没有限制。首先,似乎并非所有听众对低级别噪声的敏感度都相同。根据水印插入的侵入性和音频内容的类型,一些听众报告说能听到水印的“嗡嗡”声。
其次,扩频水印往往对音高变化非常敏感。如果发送方的频率与接收方期望的频率不同,则无法提取水印。音高变化的一个常见情况是多普勒效应。多普勒效应描述的是当发送者和接收者的移动速度不同时,音频似乎会经历频率变化的现象。当我们听到救护车的警报声在朝我们驶来、经过我们然后远离我们时音高发生变化,这就是多普勒效应。扩频水印通常非常容易受到多普勒效应的影响,如果手机和扬声器不是完全静止的,那么提取水印可能会失败,这限制了其在日常应用中的使用。
回声调制
原则上,声音在遇到耳朵范围内的每个物体时都会产生回声。我们通常听不到这些回声的原因是人类的听觉系统已经进化到可以过滤掉回声,尤其是短回声。毕竟,如果我们听到来自每个物体的每个回声,我们的感官就会不堪重负。我们只听到长时间的回声,这就是为什么我们可以在很远的距离听到回声,例如在空旷的教堂或洞穴中。回声调制技术利用这种不敏感性将数据隐藏在短回声中。目前,Intrasonics是唯一提供回声调制水印技术的公司。
回声调制水印技术涉及获取原始内容,计算其自然回声应该是什么,并将数据添加到这些回声中。这些人工回声与自然回声具有相同的结构,但放置的方式使得设备可以选择性地提取人工回声以确定水印。回声的形状决定了数据内容。如果需要,可以同时添加多个不重叠的回声以增加数据速率。
由于回声调制技术使用原始内容的回声,因此水印的可听性和可解码性取决于原始内容。例如,可以理解的是,回声调制技术无法在水印中添加静音(因为静音没有回声)。由于人工回声与随机噪声不同,因此水印听起来不像嘈杂的嗡嗡声。事实上,在我们通常经历许多回声的音频中(例如足球比赛),回声调制水印实际上是听不见的。另一方面,在我们不习惯听到回声的情况下(例如单乐器古典音乐作品),它们可能更加明显。
与扩频水印相比,回声调制技术对频率和时序变化的敏感性要低得多。回声调制水印对多普勒效应具有很强的鲁棒性,并且可以从移动的手机中轻松提取。
视觉域音频
是传统音频水印中一种较新的方法,可将数字数据隐藏在音频内容中。

图1
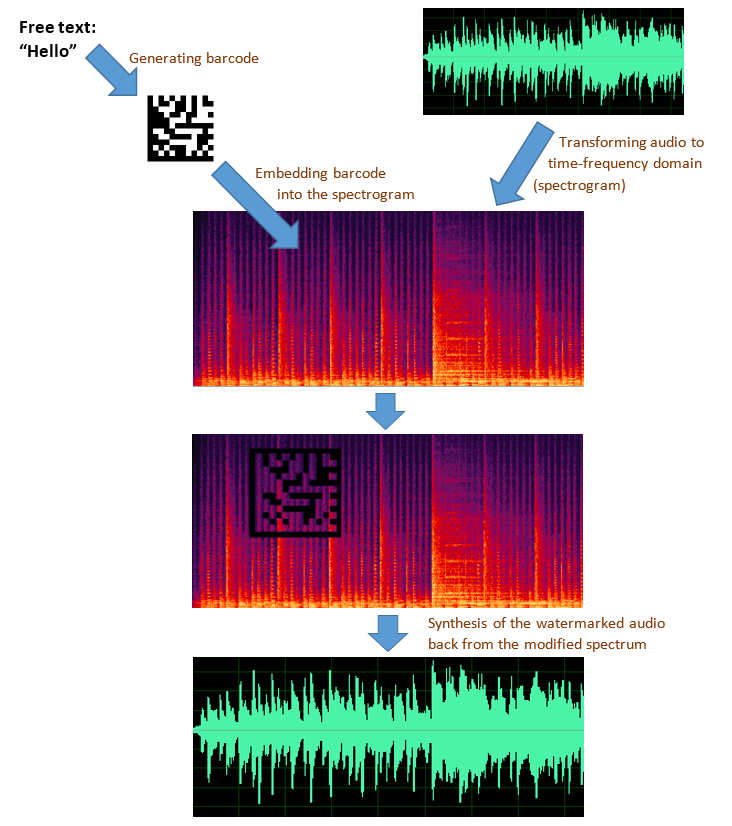
图2
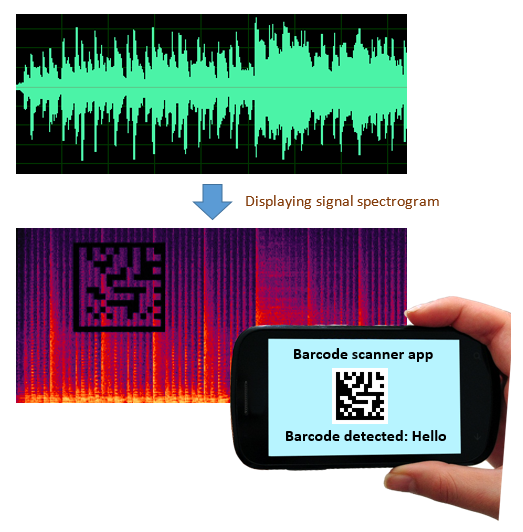
图3
声谱图是声波图形表示形式的一个特定示例。声谱图是声音随时间变化的频率频谱的直观表示。更准确地说,频谱图图像(参见图 1)是表示通过重叠信号帧的 FFT 分解获得的信号频谱图序列的颜色度图。它是音频内容图形表示的常见方式,提供非常高水平的细节并且易于视觉阅读。

我们都知道NASA的旅行者2号已经飞出太阳系,这上面带着一张黄金制作的唱片,里面有一段人类音频。下面这个视频,将一些黄金唱片的信息(图像)写入到一段音频里,再使用频谱分析软件解码。非常酷!
实际考虑
水印的可听性由水印幅度决定,即引入的水印强度。如果水印幅度非常低,它实际上将是听不见的,但只能发送很少的数据。相反,更多的数据可以通过更强的水印发送,但它将更加明显。其次,一定数量的数据用于错误校正,这确保了即使部分接收的水印也可以成功提取。错误校正补偿了阻碍人工回声检索的噪声,确保水印在严重失真或嘈杂的音频中仍然保持抗干扰性。然而,错误校正是以牺牲有用数据速率为代价的。
因此,水印质量是数据速率、抗干扰性和可听性之间的权衡。

而今天,有了AI技术的加持,音频水印向更高技术层面去发展。虽然谷歌的AI音频水印技术主要是为了给AI制作生成的音乐和音频进行识别。先听听下面由AI加入的音频水印,你听得出来差别么?

要嵌入数字水印,首先将音频波转换为频谱图,添加数字水印,然后再将其转换回音频波格式。这个过程保证了水印对人类是不可听的,并且对修改具有抵抗力。
对于AI生成的图像,它将数字水印嵌入到图像的像素中,这是肉眼无法看到的。水印被设计成能够抵抗诸如添加滤镜、改变颜色以及使用有损压缩方案(如JPEG压缩)等更改。即使图像被更改,水印仍然可以被检测到,而不会影响图像的质量。
在嵌入水印后,SynthID可以扫描音频轨道或图像以检测数字水印的存在。结果提供了置信度水平,帮助用户确定内容是否使用特定的AI模型(如用于音乐的Lyria或用于图像的Imagen)生成。
可以说,SynthID并不是缓解错误信息的全面解决方案,而是代表了一种早期的技术方法,通过实现AI生成内容的可追踪性和可识别性来增强对其的信任。因此,YouTube现在会在包含AI生成内容的视频上标记警告。
使用谷歌DeepMind的人工智能Lyria模型创建的音频,例如用YouTube新的音频生成功能制作的曲目,将被打上SynthID水印,以便人们在事后识别其人工智能生成的来源。

像SynthID这样的水印工具被视为防范生成式人工智能某些危害的重要保障。例如,乔·拜登总统关于人工智能的行政命令就呼吁制定一套新的政府主导的标准,对人工智能生成的内容进行水印处理。这是一个有前景的领域,但目前的技术远非防范假货的万灵药。
- 谷歌在AI生成的音乐中嵌入不可听的水印以识别其来源
- 使用谷歌DeepMind的AI Lyria模型创建的音频将使用SynthID进行水印处理
- 该水印人耳无法察觉,且不影响聆听体验
- 即使音频轨道被压缩、加速或减速,或者添加了额外的噪音,水印仍然可以被检测到
- 像SynthID这样的水印工具是对抗生成式AI危害的重要保障
- 当前的水印技术并不能完全防止伪造
谷歌的AI加入水印也是通过声谱图视觉水印技术,但AI技术能力更好更强,且难以破解。要嵌入数字水印,首先将音频波转换为频谱图,添加数字水印,然后再将其转换回音频波格式。这个过程保证了水印对人类是不可听的,并且对修改具有抵抗力。
AI真的在改变我们的工作与生活 ,已经沁入音频领域的角落。
更多AI内容请访问我们的“AI音频技术频道”
